Y-split
Or even better than dialling it back, if you really want to make your sound engineer happy (and give him the best chance of making your band sound amazing!) provide a clean y-split.

In this case, the engineer would receive two copies of the vocals to his desk, a clean copy straight from the microphone with nothing added to it, and a ‘dirty’ copy with the chosen effects added from your effects unit. This is by far the best scenario for your show.
Want a particular reverb for that chorus? The old fashioned telephone style effect to the intro to this sing, or the bridge of that one? You as the singer still have control of when the effects switch on and off. But by giving the engineer both a clean and a dirty copy of your vocals, he can control how much is added on the mixing desk, adding just the right amount to make your vocals sound great and work with the band, but also to work with the natural acoustics of the venue. He also now has the ability to add some of the effect into the stage wedges if the artists, but can adjust and balance how much is added, and even give it it’s own EQ if needed, which will go a long way to controlling any potential feedback issues on stage.
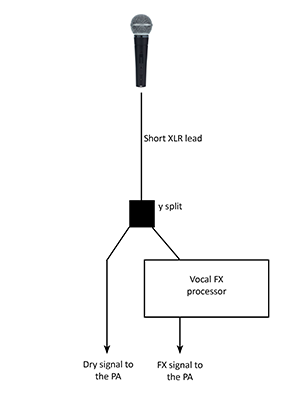
There are two main ways to accomplish this. The first is with an actual, physical y-split cable, which is where the name comes from. This will be a small adaptor that you plug into the cable coming from the microphone and physically split it into two outputs. One would then go straight into the mixing desk (through whatever stage box system the venue is using) and the second would pass through your effects processor and have the effect added, and then again be plugged into the mixing desk and PA system.
However there is a slight problem with this set up, and while simple and easy to implement there is actually a better way to do it. The issue comes because the copy of the vocal that passes through the effects unit will have a slight delay added to it. This is caused simply because it takes the processor and the electronics inside the unit a little time to process the vocal sound and add the effect to it. It will only be a few milliseconds, but for some units it is enough to negatively affect the sound when the two copies of the vocal are then combined again, one a split second behind the other. If this time difference is big enough, a slight phasing effect can be added, and it is not what you’re looking for in your search for great sounding vocals.
Instead, what is even better if you’re effects processor is able, is to give your engineer both a clean and a dirty copy from within the unit itself.
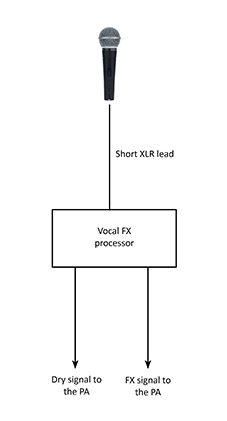
of the processor, using the L and R outputs
Most of these units will have a single input connection for you to be able to plug your microphone in, but they have a stereo output that goes to the PA system. We want to change the settings for these to use them as our two different outputs, the Left one as our clean output that has no effects added to it, and the Right one as the dirty output with the effects added. How exactly this is accomplished (or whether it can be) will be different from unit to unit, but the idea is that since both copies have passed through the effects unit, we wont have the slight time delay issue we had using a physical y-split. The two copies of the vocals will stay perfectly in time, or at least be much closer, and we will remove the phasing sound that we wish to avoid.
Conclusion
Vocal effects processors can add a lot to your sound at your shows and live events. However they must be used with care to achieve optimum results and not detract from your performance. Hopefully, by following some of the advice here, you vocals will be well on their way to achieving that Killer Live Sound.